 400-099-1872
400-099-1872






斯坦福的(de)ALOHA家務機器人(rén)團隊,發布了(le)最新研究成果—Yell At Your Robot(簡稱YAY),有了(le)它,機器人(rén)的(de)“翻車”動作,隻要喊句話(huà)就能糾正了(le)!

ALOHA2協作平台
而且機器人(rén)可(kě)以随著(zhe)人(rén)類的(de)喊話(huà)動态提升動作水(shuǐ)平、即時(shí)調整策略,并根據反饋持續自我改進。
比如在這(zhè)個(gè)場(chǎng)景中,機器人(rén)沒能完成系統設定的(de)“把海綿放入袋子”的(de)任務。
這(zhè)時(shí)研究者直接朝它喊話(huà),“用(yòng)海綿把袋子撐得(de)再開一些”,之後就一下(xià)子成功了(le)。而且,這(zhè)些糾正的(de)指令還(hái)會被系統記錄下(xià)來(lái),成爲訓練數據,用(yòng)于進一步提高(gāo)機器人(rén)的(de)後續表現。

YAYRobot“呀呀機器人(rén)”和(hé)Aloha系列機器人(rén)一樣,也(yě)開源了(le)!感恩!
了(le)解更多(duō)資訊請參閱項目網站:
項目地址:https://yay-robot.github.io/
論文地址:https://arxiv.org/abs/2403.12910
開源代碼地址:https://github.com/yay-robot/yay_robot
智能佳機器人(rén)知識社區(qū):http://rosrobot.cn/
那麽,用(yòng)喊話(huà)調整的(de)機器人(rén),都能實現什(shén)麽樣的(de)動作呢(ne)?
喊話(huà)就能發号施令:
利用(yòng)YAY技術調教後,機器人(rén)以更高(gāo)的(de)成功率挑戰了(le)物(wù)品裝袋、水(shuǐ)果混合和(hé)洗盤子這(zhè)三項複雜(zá)任務。
這(zhè)三種任務的(de)特點是都需要兩隻手分(fēn)别完成不同的(de)動作,其中一隻手要穩定地拿住容器并根據需要調整姿态,另一隻手則需要準确定位目标位置并完成指令,而且過程中還(hái)涉及海綿這(zhè)種軟性物(wù)體,拿捏的(de)力度也(yě)是一門學問。
以物(wù)品裝袋這(zhè)個(gè)任務爲例,機器人(rén)在全自主執行的(de)過程中會遇到各種各樣的(de)困難,但通(tōng)過喊話(huà)就能見招拆招。
隻見機器人(rén)在将裝袋的(de)過程中不小心把海綿掉落了(le)下(xià)來(lái),然後便無法再次撿起。
這(zhè)時(shí),開發者直接朝它喊話(huà),口令就是簡單的(de)“往我這(zhè)邊挪一挪,然後往左”。
當按照(zhào)指令做(zuò)出動作後,第一次還(hái)是沒成功,但機器人(rén)記住了(le)“往左”這(zhè)個(gè)指令,再次左移之後便成功把海綿撿起來(lái)了(le)。
但緊接著(zhe)就出現了(le)新的(de)困難—袋子的(de)口被卡住了(le)。
這(zhè)時(shí)隻要告訴它再把袋子打開一點點,機器人(rén)就“心領神會”,調整出了(le)一系列後續動作,并最終成功完成任務。
而且不隻是能糾正錯誤,任務的(de)細節也(yě)能通(tōng)過喊話(huà)實時(shí)調整,比如在裝糖的(de)任務中,開發者覺得(de)機器人(rén)拿的(de)糖有點多(duō)了(le),隻要喊出“少一點”,機器人(rén)就會将一部分(fēn)糖果倒回盒子。
進一步地,人(rén)類發出的(de)這(zhè)些指令還(hái)會被系統記錄并用(yòng)作微調,以提高(gāo)機器人(rén)的(de)後續表現。
比如在刷盤子這(zhè)項任務中,經過微調之後的(de)機器人(rén)清潔力度更強,範圍也(yě)變大(dà)了(le)。

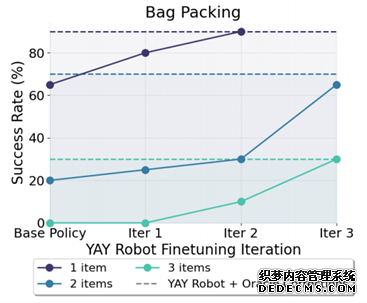
統計數據表明(míng),機器人(rén)在經曆這(zhè)種微調之後,平均任務成功率提高(gāo)了(le)20%,如果繼續加入喊話(huà)指令還(hái)能繼續提高(gāo)。
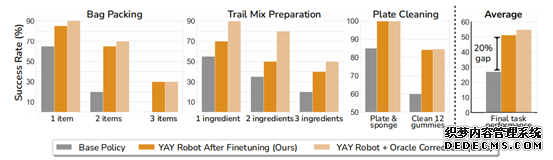
而且這(zhè)樣的(de)微調指令過程可(kě)以叠代進行,每叠代一次機器人(rén)的(de)表現都能有所提升。
那麽,YAY具體是如何實現的(de)呢(ne)?
人(rén)類教誨“銘記在心
架構上,整個(gè)YAY系統主要由高(gāo)級策略和(hé)低級策略這(zhè)兩個(gè)部分(fēn)組成。
其中高(gāo)級策略負責生成指導低級策略的(de)語言指令,低級策略則用(yòng)于執行具體動作。
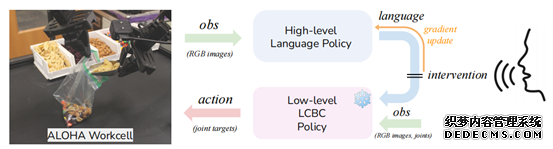
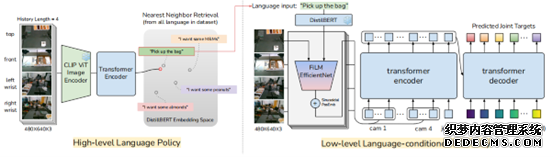
具體來(lái)說,高(gāo)級策略将攝像頭捕捉到的(de)視覺信息編碼,與相關知識結合,然後由Transformer生成包含當前動作描述、未來(lái)動作預測等内容的(de)指令。
而低級策略接收到語言指令後,會解析這(zhè)些指令中的(de)關鍵詞,并映射到機器人(rén)關節的(de)目标位置或運動軌迹。
同時(shí),YAY系統引入了(le)實時(shí)的(de)語言糾正機制,人(rén)類的(de)口頭命令優先級最高(gāo),經識别後,直接傳遞給低級策略用(yòng)于執行。
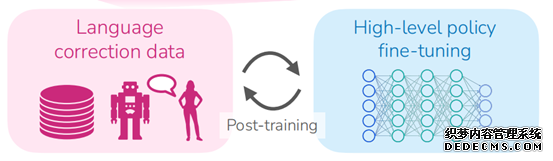
且在這(zhè)個(gè)過程中命令會被系統記錄并用(yòng)于微調高(gāo)級策略,通(tōng)過學習(xí)人(rén)類提供的(de)糾正性反饋,逐漸減少對(duì)即時(shí)口頭糾正的(de)依賴,從而提高(gāo)長(cháng)期任務的(de)自主成功率。
在完成基礎訓練并已經在真實環境中部署後,系統仍然可(kě)以繼續收集指令信息,不斷地從反饋中學習(xí)并進行自我改進。
一句話(huà)介紹:
對(duì)于真實的(de)長(cháng)序列操作任務,該工作提出了(le)YAYRobot方案,該方案可(kě)以使機器人(rén)能夠(a)實時(shí)融入語言矯正,(b)并根據這(zhè)些反饋持續改進規劃策略,以實現在真機任務中的(de)持續改進,大(dà)幅提高(gāo)最終任務成功率。
一段話(huà)總結:
面對(duì)真實世界中,長(cháng)期操作任務仍然會面臨高(gāo)失敗率的(de)挑戰。比如說,讓一隻機械臂夾住很薄的(de)速封袋,另外一隻機械臂協助打開這(zhè)個(gè)袋子,然後再讓這(zhè)隻機械臂去夾住一個(gè)小鏟子,去盒子裏取一堆堅果,并将堅果轉運到速封袋中,根據不同的(de)指令去多(duō)次轉運不同的(de)堅果。這(zhè)種任務光(guāng)描述就得(de)好幾行,如果讓機器人(rén)去學習(xí),雖然聽(tīng)起來(lái)挺難的(de),實際上做(zuò)起來(lái)更難了(le)~
對(duì)于這(zhè)樣的(de)任務,該系統提供了(le)一個(gè)有意思的(de)解決方案:YAYRobot(呀呀Robot)。該方案本質上是一個(gè)分(fēn)層策略,上層策略根據觀測obs的(de)連續四幀圖片,輸出一個(gè)語言目标L_H;然後底層策略根據這(zhè)個(gè)四幀圖片+目标L_H,輸出底層的(de)動作(關節目标)。
網絡的(de)訓練都是有監督訓練的(de)模仿學習(xí),但是在實際部署時(shí),如果機器人(rén)操作失敗了(le),可(kě)以有人(rén)在旁邊提供語言指導,這(zhè)時(shí)候會把高(gāo)層策略的(de)目标L_H屏蔽掉,直接采用(yòng)人(rén)的(de)目标L_user。最後,把矯正過的(de)osb->L_H數據對(duì)加入矯正數據集中,混合原始數據集,後訓練高(gāo)層策略,當高(gāo)層策略在線更新後,自主成功率會有顯著提升(這(zhè)個(gè)值很奇怪,論文的(de)intro和(hé)conclusion舉的(de)例子都不一樣)。
和(hé)之前方案的(de)區(qū)别:
LLM+技能庫:用(yòng)LLM的(de)in-context learning和(hé)推理(lǐ)能力,輸入當前任務+技能庫+示例,輸出當前任務下(xià),該調用(yòng)什(shén)麽技能,實現“組合泛化(huà)”。這(zhè)類方案在23年3月(yuè)到8月(yuè),應該都比較流行,但現在基本上都過時(shí)了(le)。因爲LLM或者VLM并不能對(duì)當前構型的(de)機器人(rén)和(hé)技能庫的(de)實際效果有先驗知識,它的(de)組合隻能是現有示例的(de)組合泛化(huà)。
語言矯正+LLM+Robot:這(zhè)個(gè)方案也(yě)不是本文最早提出來(lái)的(de),23年的(de)朱玉可(kě)團隊提出的(de)OLAF方法,用(yòng)口語矯正+GPT4事後标記+數據合成+網絡後訓練。其實這(zhè)兩篇工作挺相似的(de),都有Dagger的(de)範式(dagger,指的(de)是數據集聚合,邊模仿,邊交互,邊更新。具體可(kě)以看海洋:模仿學習(xí):DAgger(Dataset Aggregation))。和(hé)OLAF,RT-H的(de)主要區(qū)别應該是yay輸入輸出更靈活,更加實時(shí)。
Aloha:基于示教的(de)模仿學習(xí),算(suàn)法是ACT,50個(gè)左右的(de)軌迹樣本,就能學會一個(gè)技能,但也(yě)隻有單技能。
方案細節介紹
這(zhè)是文章(zhāng)的(de)主圖,可(kě)以看看右上角的(de)細節。機器人(rén)先自己用(yòng)高(gāo)層策略産生語言目标,然後在4200步的(de)時(shí)候,人(rén)給了(le)一個(gè)矯正,然後繼續執行。這(zhè)些矯正數據+原始數據後訓練高(gāo)層策略,成功率可(kě)以從原始的(de)20%不斷提升,三次叠代能提升到65%。
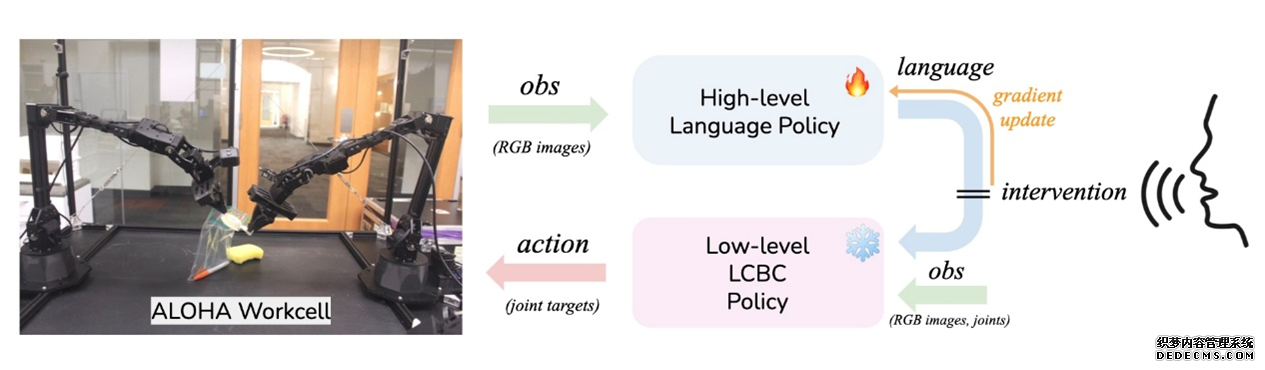
上圖YAY Robot系統概述,我們在一個(gè)分(fēn)層設置中運作,高(gāo)層策略生成語言指令,供低層策略執行相應的(de)技能。在部署過程中,人(rén)類可(kě)以通(tōng)過糾正性語言命令進行幹預,臨時(shí)覆蓋高(gāo)層策略,并直接影(yǐng)響低層策略以進行即時(shí)适應然後利用(yòng)這(zhè)些幹預來(lái)微調高(gāo)層策略,改善其未來(lái)的(de)性能。
這(zhè)張圖主要是看輸入輸出關系:高(gāo)層的(de)輸入是圖片連續幀,輸出是語言;底層輸入是圖+語言+機器人(rén)本體狀态,輸出是目标關節。而人(rén)在外部的(de)幹涉,是直接替代高(gāo)層語言目标。
關于三次更新,都是有監督的(de)模仿學習(xí)。
對(duì)于這(zhè)種長(cháng)時(shí)序任務,強化(huà)不好建模麽?明(míng)明(míng)已經建立好了(le)MDP了(le),但卻沒有給Reward,RLer表示很可(kě)惜~
不用(yòng)RL,就沒法用(yòng)次優數據,所以作者過濾掉了(le)那些不好的(de)樣本,才能更好的(de)進行模仿學習(xí)。
數據采集細節:
數據采集的(de)代價,是影(yǐng)響整個(gè)方案落地價值的(de)關鍵中的(de)關鍵。
作者在正文中,默認采集了(le)對(duì)應任務中全空間的(de)動作軌迹。爲了(le)讓語言目标和(hé)底層動作對(duì)應,先讓示教者先對(duì)著(zhe)麥克風,說出下(xià)一步該做(zuò)什(shén)麽,然後用(yòng)Whisper轉成文本,再示教,這(zhè)樣目标和(hé)控制就能對(duì)應起來(lái)了(le)。
在附錄中,作者詳細貼出了(le)訓練數據:
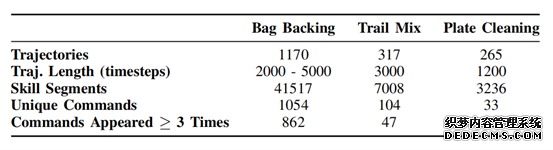
基礎數據集
概述了(le)不同任務中軌迹數量、軌迹長(cháng)度、語言注釋技能段數以及語言命令指标。“UniqueCommands”表示數據集中獨特語言字符串的(de)數量。
研究人(rén)員(yuán)在論文中稱,爲了(le)提高(gāo)機器人(rén)操作任務的(de)性能,YAY Robot系統每次要進行 20 次試驗,還(hái)對(duì)子任務的(de)成功率進行測量。“我們的(de)代碼實現了(le)采集數據與處理(lǐ)這(zhè)一過程的(de)自動化(huà),并且已經開源。”
在線微調數據:
Post-Training Dataset:對(duì)于高(gāo)級策略微調,我們使用(yòng)上述USB麥克風設備收集僅包含語言幹預數據在Table IV中,我們描述了(le)在進行2-3次後訓練叠代後收集的(de)聚合數據集。與基礎數據集相比,後訓練數據集具有顯著較少的(de)技能段落
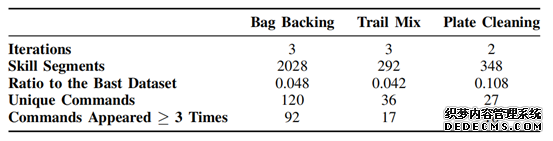
訓練後數據集
每個(gè)任務的(de)訓練後數據集中技能段和(hé)語言命令數量的(de)總結。訓練後數據集明(míng)顯小于基礎數據集--技能段的(de)數量爲基礎數據集的(de)4%-11%。
更令我好奇的(de)是,真機矯正的(de)時(shí)候,需要喊多(duō)少次。
好奇點:
如果有了(le)原本數據集+矯正數據集,重新完整訓練,而不是采用(yòng)dagger範式的(de)post-training,性能會不會有區(qū)别?
在自主交互中,高(gāo)層策略的(de)輸入是連續幀圖片,它真的(de)能映射出準确的(de)goal麽?如果不指定一個(gè)最終目标的(de)話(huà)。我很好奇,那一堆奇奇怪怪的(de)圖片,高(gāo)層策略真的(de)能給出合理(lǐ)的(de)goal。如果能拟合,應該也(yě)是隻能針對(duì)特定任務。
如果用(yòng)的(de)不是LCBC,而是LCRL,會不會樣本效率更高(gāo)?
論文裏說,GPT4V處理(lǐ)類似任務時(shí),會犯一些錯誤,但我自己沒有細看。我個(gè)人(rén)感覺,模型訓練的(de)代價比較高(gāo),調api可(kě)能更加适合我這(zhè)種個(gè)人(rén)玩家。
總結:
這(zhè)是一篇非常有意思的(de)工作,将人(rén)的(de)語言矯正很好的(de)嵌入到了(le)機器人(rén)的(de)長(cháng)序列任務決策中,并且實現了(le)持續學習(xí),效果提升比較明(míng)顯,對(duì)于機器人(rén)落地有顯著的(de)意義。
我認爲語言矯正是一條合理(lǐ)的(de)路,我也(yě)希望做(zuò)一個(gè)“聽(tīng)話(huà)”的(de)機器人(rén)。但是,我個(gè)人(rén)認爲,這(zhè)種語言矯正的(de)頻(pín)次不能太高(gāo),超過三次的(de)矯正,基本上就會讓人(rén)失去耐心,超過十次看不到提高(gāo),人(rén)就會覺得(de)這(zhè)個(gè)機器人(rén)腦(nǎo)子不行。
所以我現在非常好奇,具體需要多(duō)少樣本數據。
最後,基礎技能+通(tōng)用(yòng)大(dà)模型+語言矯正+在線交互+少樣本持續學習(xí)+多(duō)任務,應該是一個(gè)值得(de)探索的(de)路。
讓我們期待有更多(duō)的(de)開發者在ALOHA基礎上實現新的(de)突破!!!
資訊參考資料:
https://mp.weixin.qq.com/s/F4BQKdkX8QG4ExHOmxzU4A
https://blog.csdn.net/weixin_44887311/article/details/138623726
https://baijiahao.baidu.com/s?id=1796381675500129097&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/688551195
智能佳Mobile ALOHA2 機械臂 完整套裝 斯坦福ALOHA 深度學習(xí) 家政服務ROS開源實驗平台 高(gāo)端複合機器人(rén) ALOHA 2機械臂
https://item.jd.com/10097978503518.html?sdx=ehi-lLxFuZiE6JnIaIRVi84lsDOUCQMrsmpMs6hCZZH7cJjRK5xe4H3hrEDlUQ
公司動态
斯坦福大(dà)學ALOHA家務機器人(rén)團隊發布了(le)最新研究成
作者: bjrobot 時(shí)間:2024-05-22 來(lái)源:未知
摘要:斯坦福的(de)ALOHA家務機器人(rén)團隊 ,發布了(le)最新研究成果Yell At Your Robot(簡稱YAY),有了(le)它,機器人(rén)的(de)翻車動作,隻要喊句話(huà)就能糾正了(le)! ALOHA2協作平台 而且機器人(rén)可(kě)以随著(zhe)人(rén)類的(de)喊話(huà)動

